Introduction
The 2020 presidential election in the United States was polarizing for the American people, perhaps even historically so, as Americans grappled with casting their votes for Joe Biden or President Donald Trump in light of major events that took place in 2020, including the onset of the COVID-19 pandemic at the beginning of the year and the racial protests and riots sparked by the murder of George Floyd at the hands of the police in May. Happenings such as these have led the American people to regard the year 2020 as generally negative—it was common to hear statements in the media and amongst peers such as “2020 is the worst year ever” or “I just want 2020 to be over.” There is also talk amongst the media and general public that, politically, Americans are “more divided than ever,” largely in reference to conflicting opinions about Donald Trump’s controversial presidency.
We are curious if there is empirical evidence of Americans’ attitudes towards politics becoming increasingly negative and polarized as suggested by these common sentiments, and how attitudes between and within political parties may have shifted in recent years. To do this, we analyze Twitter data related to the 2016 and 2020 presidential elections, specifically, as Twitter has become a popular platform for voters and candidates to express their opinions and exchange information, and the elections offer two distinct political events to measure change between. In this investigation, we develop a method of assigning political leanings to Twitter users and perform sentiment analysis and permutation testing on different groups of tweets between the two election years to assess if there are stasticially significant shifts in sentiment from 2016 to 2020, hypothesizing that tweets have become more negative and less neutral between the two years.
The Data
We use two different datasets of tweets in this investigation, one for each election. The 2016 dataset was collected by researchers at Harvard and the 2020 dataset was collected by researchers at USC. Both groups collected tweets by tracking accounts and keywords affiliated with the elections using Twitter’s API. Each raw dataset consists of text files of tweet IDs. A tweet ID is a numerical identifier associated with a specific tweet, the full information of which is retrieved in process called “hydration” using a tool called Twarc that is linked to Twitter’s API. Twarc returns the full information for tweets in json format, and each hydrated tweet contains data fields such as the full text of the tweet, the hashtags it uses, the users it mentions, if it was an original tweet or retweet, etc., as well as information about the Twitter user who authored the tweet.
To maintain uniformity for sentiment analysis, we filter out tweets in languages other than English. Also, the two datasets were collected by different groups that used different keyword searches to gather election-related tweets, so for our analysis to not be affected by this, we had to unify them under a universal keyword search. The keyword search used for the 2020 dataset was broader than that used for the 2016 dataset, so we filter the 2020 dataset using the 2016 keywords, changing the names of the candidates to align with the 2020 election. Our final datasets consist of 414,713 tweets from 2016 and 500,000 tweets from 2020.
Our Approach
Identifying the Political Left and Right
We have two ways of assigning political leanings to tweets: if they were authored by partisan news sources or politicians, or if they use politically-charged hashtags. For the first way, we made lists of right- and left-leaning Twitter accounts of partisan news sources by selecting those that are determined to be far-left or far-right according to statistical analysis of popular news outlets performed by AllSides.com. For the politicians, we add to these lists the Twitter accounts of all of the candidates listed on the 2016 and 2020 Democratic and Republican Party presidential primaries’ Wikipedia pages. So with this, we had lists of relatively influential Twitter users whose political leanings are well-defined.
For the second way of identifying left- and right-leaning tweets, we referred to their hashtag usage. We hand-picked clearly left- and clearly right-leaning hashtags among commonly used hashtags within the sets of tweets for both years. For 2016, for example, left-leaning hashtags included “voteblue” and “donthecon” and right-leaning hashtags included “maga” and “lockherup”. Then, for each year, we made left and right subsets of users by selecting those who used the respective hashtags. We combined these users with the lists of politicians and partisan news sites accounts, then gathered all tweets from the datasets authored by these accounts to get our final left- and right-leaning subsets of tweets.
After assigning political leanings to some of the users, we identified “dialogue” happening between and within the left and right political spheres by analyzing the tweets’ user mentions. We classified the dialogue occurring as either L-L, L-R, R-L, or R-R depending on the leaning of the author of the tweet and that of the user(s) they mention. For example, if a tweet was authored by a left-leaning user and mentions one or more right-leaning users, it was classified as being an instance of L-R dialogue. These subsets of dialogue gave us a way of narrowing down where shifts in sentiment might have occurred between 2016 and 2020—for example, we could see if attitudes among the left towards the right became more negative or if they directed more “charged” language towards them, and vice versa.
Sentiment Analysis
We use a Python library called Vader to perform sentiment analysis on the tweets. Vader uses a dictionary in order to map lexical features to sentiment scores, which are emotion intensities. By summing up the intensity of each word in a text, Vader can obtain the overall text’s sentiment score. Vader is intuitive, in that it understands the implications of capitalization and punctuation. It also take the usage of negative words such as “not” or “no” into account. Vader has four classes of sentiments that it assigns these scores to. These classes include positive, negative, neutral, and compound. The compound class is an aggregated score of the first three classes and it ranges from -1.0 to +1.0. These compound scores can tell us whether or not our text was expressing a positive, negative, or neutral opinion.
The following sets of plots for each year show the distributions of compound scores for all tweets, for the left and right subsets we identified, and for the four types of dialogue we identified. We can see that the distributions appear very similar, both between the groups for each year and across the two years.
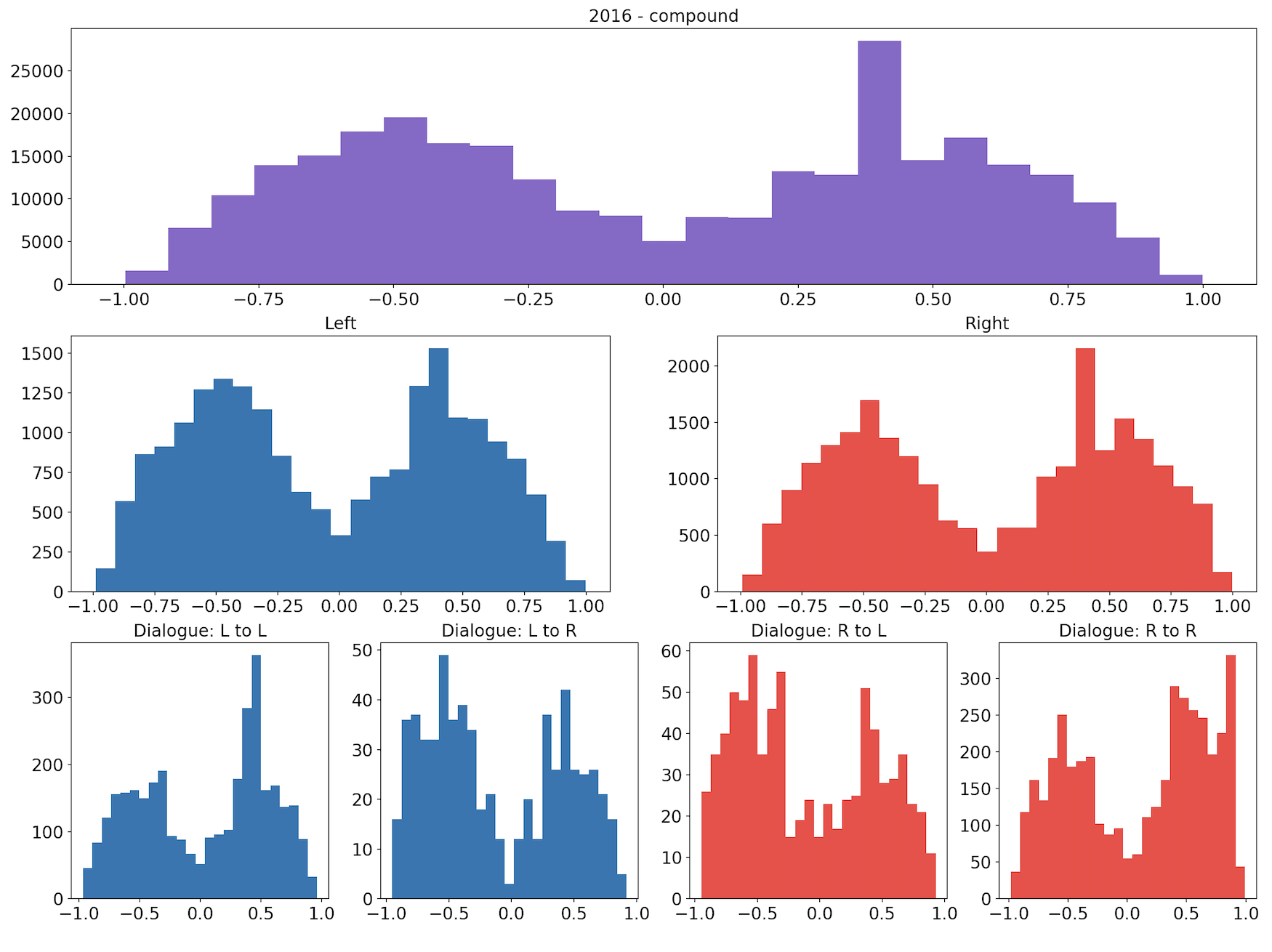
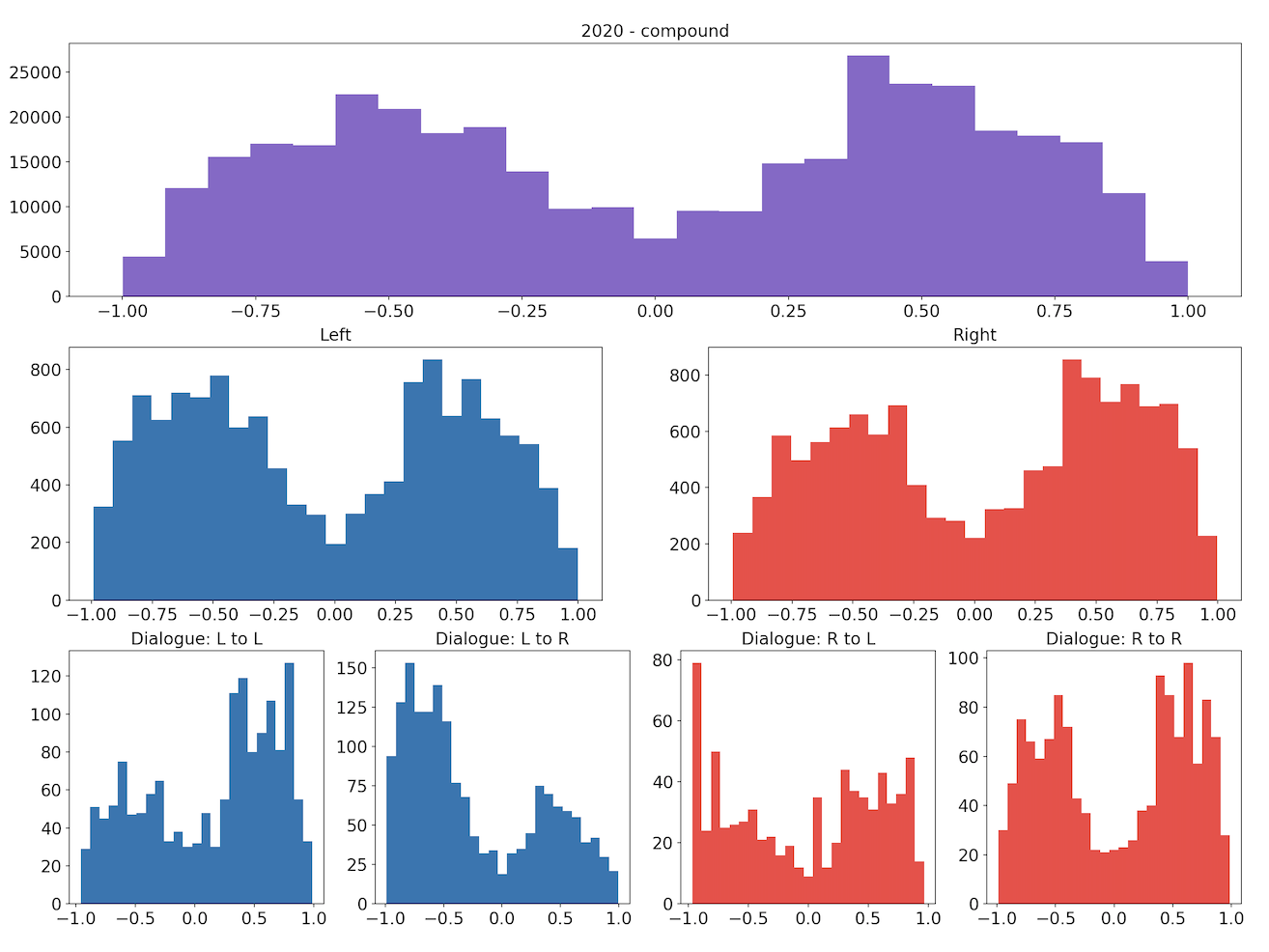
Similarly, the following sets of plots show how the tweets’ neutrality scores are distributed.
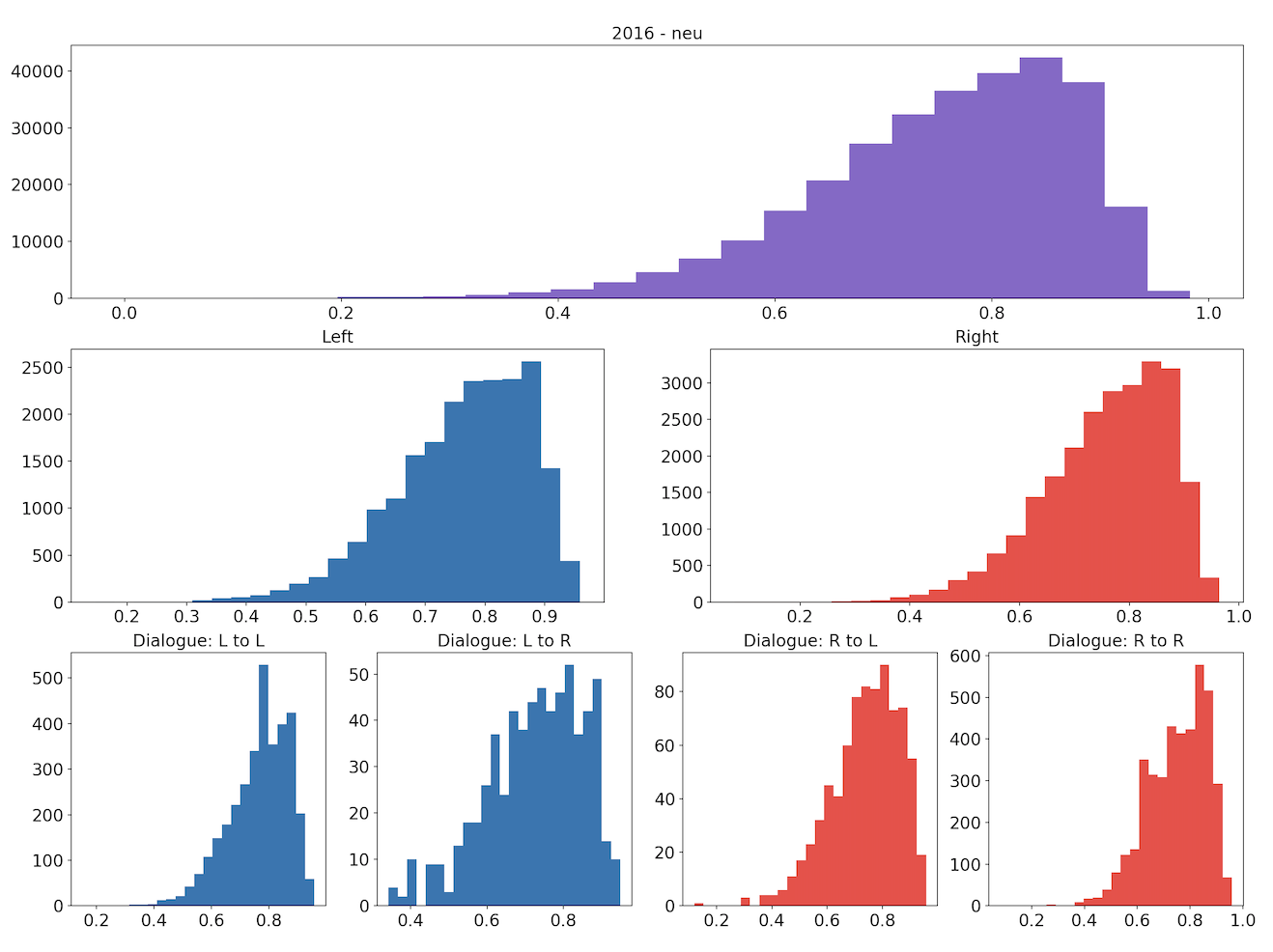
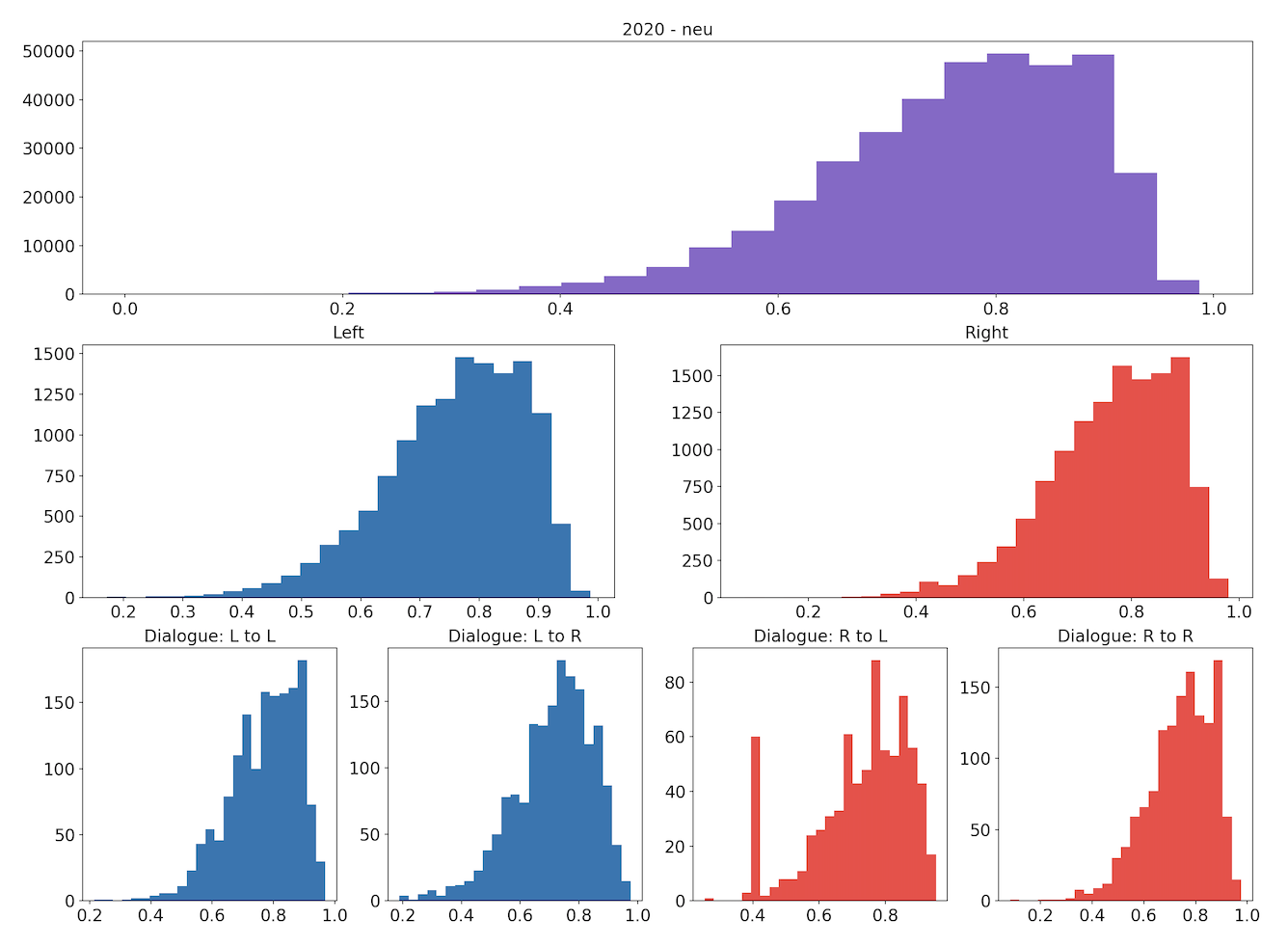
Visually, the distributions of both the compound and neutrality scores are similar across the different groupings. We conduct permutation testing to determine if there are statistically significant differences between distributions across the two years.
Permutation Testing
To determine if the results of our sentiment analysis were statistically significant, we conducted permutation tests on the differences in mean compound score and neutrality between 2020 and 2016 for different groupings of our data: the data overall; the left and right subsets; and the left-left, left-right, right-left and right-right dialogue subsets. We stated that the null hypothesis was that there was no change in the compound score or neutrality score between the two years. Using the mean as the test statistic, we calculated the observed difference, randomly sampled the two distributions, and found the resulting p values and interpret them based on a 95% confidence level.
The following plots show the distribution of the difference of means for the compound scores, with the dotted red lines indicating the observed differences.
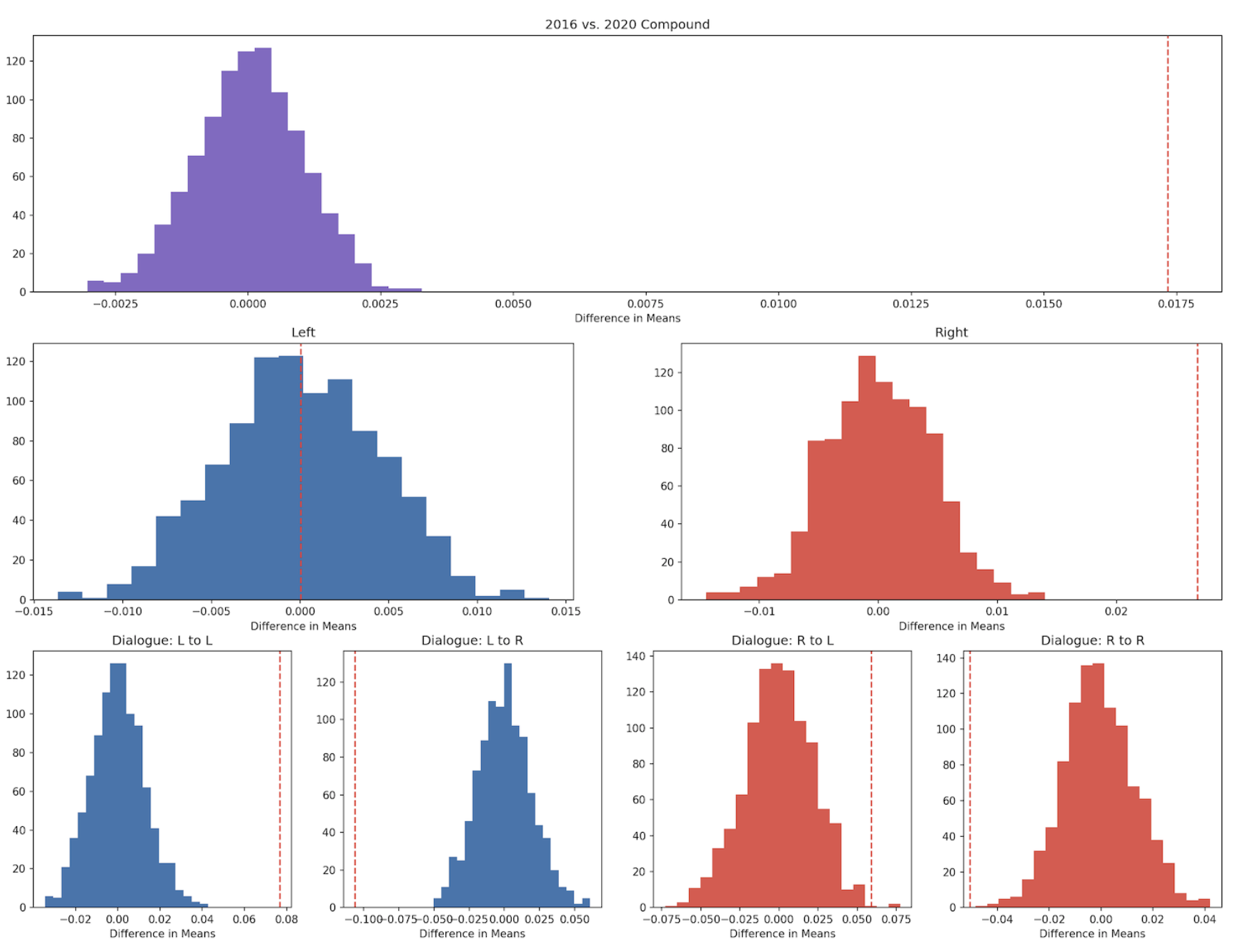
These results for Compound scores are inconclusive, as the direction of change differs depending on the subset. There is no detectable difference in Compound score for left-leaning tweets (p=0.49), whereas right-leaning tweets were conclusively more positive. As for dialogue, L-L and R-L dialogue became more positive from 2016 to 2020 and L-R and R-R dialogue became more negative.
The following plots show the distribution of the difference of means for the neutrality scores.
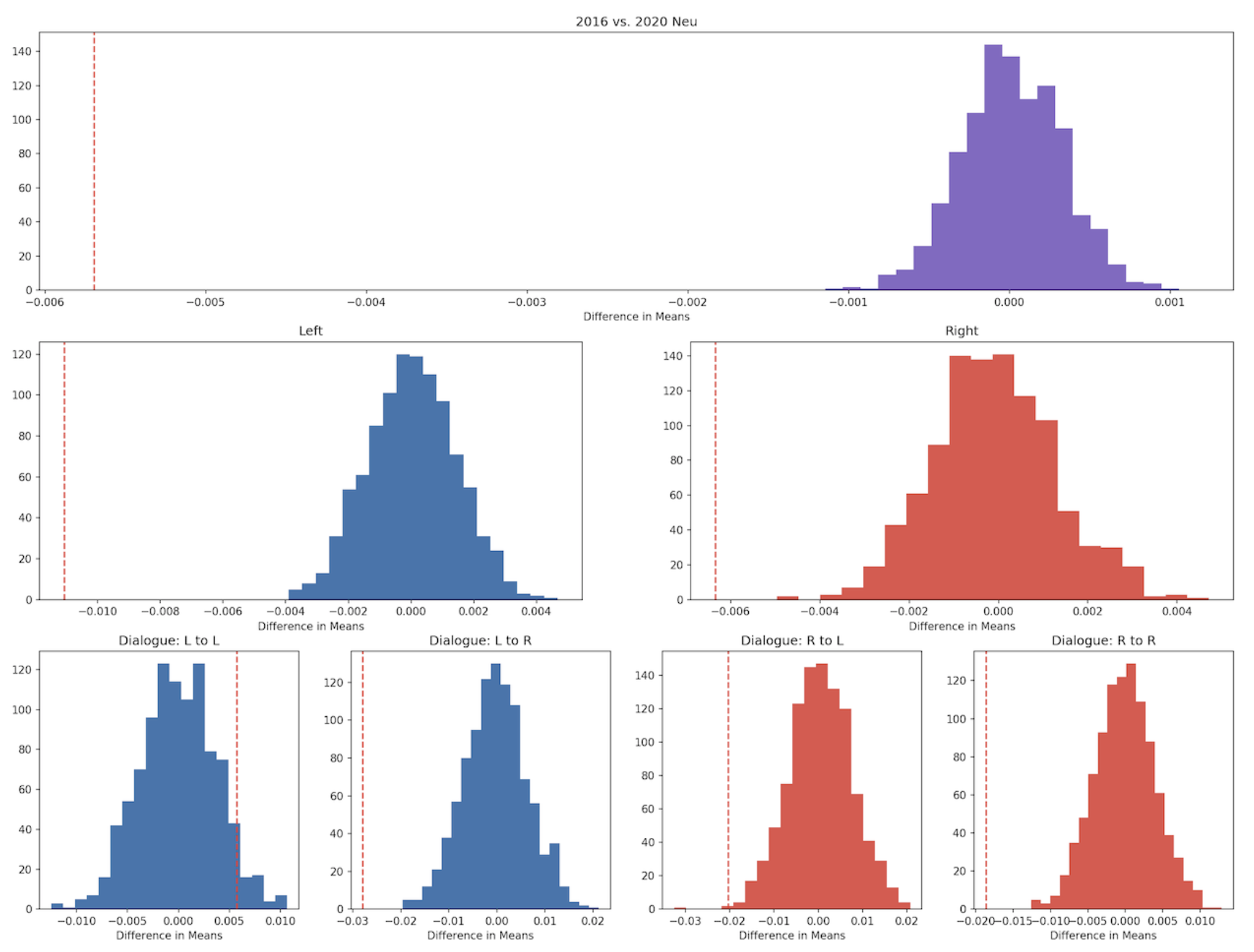
From these results, we can see that, overall, the 2020 tweets were overwhelmingly more positive and less neutral than the 2016 tweets. With the exception of the L-L dialogue subset, for which the results are inconclusive (p=0.052), tweets used less neutral language in 2020 than in 2016 across all subsets.
Conclusions
In conclusion, we found that the 2020 tweets were actually overwhelmingly more positive and less neutral when compared to the 2016 tweets. This disproves our hypothesis which stated that between 2016 and 2020, there will be an overall shift towards a more negative sentiment and less neutrality. Specifically between left-leaning users who mentioned right-leaning users, there was a noticeable decrease in neutrality and increase in negative sentiment. We can conclude that there seems to be an increase in political polarization and negative feelings from those who are left-identified to those who are right-identified, and this is reflected in stronger and more politically-charged tweets.
Interestingly, the dialogue between right-leaning users who mention left-leaning users became more positive between the two cycles, indicating that although the left-leaning users might have interacted with the right more aggressively it is not the same vice versa. In addition, the dialogue within left users demonstrated a more positive shift, but that within right users became more negative, indicating that we can’t make conclusive statements in terms of the sentiment shift within a certain political party, but perhaps there was more optimism within the left-leaning users with the new hope that came with the new election cycle, and more worry or pessimism within the right-leaning users. Overall, although there was an general positive shift of tweets regarding the election between the two cycles, we were able to gain interesting insights by examining the dialogue between users and the two groups.
One limitation of our approach is the size of the data that we used. After filtering each of our datasets into subsets, some of these smaller groups had only a fairly small number of tweets left for us to analyze. Also Twitter demographics could have made our results a bit misleading because the largest age demographic that is active on Twitter is from 25-34 years old, and more than 50% of people in this age category are generally left-leaning.
Future Work
In the future, it would be interesting to expand our dataset to include the political tweets from a longer, continuous time period to observe how these shifting attitudes in politics occur over time. Also it would be interesting to include classification in our project so we would be able to predict what group a user might fall in depending on the text of their tweets.
For more details see our project’s GitHub repository
Project site: hbpeters.github.io/2016-2020_pres_elections_twitter